Innovación y tecnología se nutren mutuamente y adoptarlas ya no es una opción.
Por ello, te ayudamos a capturar toda la data interna y externa, institucionalizar la toma de decisiones a través de Business Analytics, tener procesos inteligentes y automáticos y finalmente una estrategia de inteligencia artificial para optimizar la operación y predecir lo que se viene.
Acompañamos a las organizaciones en cada etapa de su adopción de inteligencia artificial, desde la estrategia y los primeros casos de uso hasta soluciones productivas que transforman procesos, reducen costos y generan valor de negocio tangible.
Sistema de monitoreo avanzado basado en multiagentes de IA generativa que permite la toma de decisiones en tiempo real a partir del análisis continuo de datos.
Repositorio de datos que puede ser almacenado en la infraestructura de la empresa, donde con flexibilidad podemos guardar el máximo de la información que recolectamos.
Del chatbot a una interacción más real. Buscamos que cada consulta se resuelva mediante el agente, reduciendo la intervención humana, sin sacrificar precisión ni trazabilidad.
De 5% a 98%: Adopción de Copilot 365 en el sector bancario
Cómo un banco líder en Argentina convirtió miles de licencias de IA generativa en hábitos de trabajo concretos, y alcanzó sus metas de adopción en un trimestre.
Cómo una plataforma de streaming deportivo aceleró la toma de decisiones al democratizar el acceso a sus datos integrando Amazon Bedrock y Redshift directamente en Slack.
Detección temprana de fallas y predicción de merma en pozos petroleros
Cómo el análisis avanzado de datos y Machine Learning permiten anticipar el deterioro en bombas electro-sumergibles, asegurando la continuidad productiva en la industria de Oil & Gas.
Transformación de la atención comercial con IA conversacional en el sector automotriz
El despliegue de un agente conversacional RAG transformó el proceso de ventas de un grupo automotriz en México, habilitando atención continua por WhatsApp y voz, agendamiento inteligente y trazabilidad completa de datos en el CRM.
Por qué más del 90% de los proyectos de IA en banca no escala (y cómo evitarlo)
Qué obstáculos frenan la llegada a producción y por qué la infraestructura, los datos y la alineación con el negocio son mucho más importantes que el modelo.
Servicios financieros en la era agentic: Modernizar sin perder escala, control ni velocidad
Claves de arquitectura, datos y estrategia para convertir iniciativas de IA en capacidades operativas reales. Un paper para equipos de tecnología y decisores del sector financiero en LATAM.
Arquitectura informática que combina una nube privada y una pública de forma que entreguen un conjunto flexible de servicios.
Esto significa que las cargas de trabajo migran de manera fluida y transparente entre un entorno y el otro de acuerdo a las necesidades que tenga la empresa en cada momento.
Optimización operativa y escalado automático para portales de gestión académica
Cómo un grupo educativo líder modernizó la infraestructura de sus plataformas estudiantiles hacia una arquitectura de contenedores, logrando despliegues automatizados y eliminando el mantenimiento de servidores.
Automatización de operaciones, mayor seguridad y reducción de costos en la nube
Estrategia integral de Cloud Operations que permitió modernizar y encapsular aplicaciones críticas, fortaleció la seguridad, automatizó la operación y proyectó significativos ahorros.
Gobernanza Cloud: Nueva era operativa en empresa líder de Servicios Financieros
Migración integral y gestión operativa proactiva en AWS, optimizando seguridad, eficiencia y agilidad para impulsar la transformación digital en empresa líder.
Banca sin core: Las APIs redefinen la ventaja competitiva
La agilidad y la flexibilidad en el sector financiero surgen hoy de arquitecturas abiertas capaces de vincular servicios, integrarse con ecosistemas y desplegar rápidamente nuevos canales digitales.
¿Cómo asegurar ambientes de APIs? ¿Cómo utilizar las tecnologías más avanzadas sin quedar expuesto? Esto y otros temas relacionados, han sido expuestos en el presente webinar.
Desde Nubiral analizamos y dimensionamos cada proyecto de tu empresa con el fin de mejorar la eficiencia de tu infraestructura TI, diseñando soluciones flexibles de alto rendimiento basadas en la experiencia de nuestros profesionales, los últimos avances tecnológicos y las tendencias actuales de cada industria.
De la fragmentación digital a una plataforma lista para el open banking
Banco Columbia tenía los productos, la visión y la ambición de crecer digitalmente. Lo que necesitaba era una plataforma que pudiera sostener ese crecimiento sin fisuras.
Migración estratégica a GitHub Enterprise para optimizar el ciclo de desarrollo
Una de las principales plataformas financieras digitales de Colombia unificó sus flujos DevOps en GitHub, fortaleciendo la colaboración y la gobernanza tecnológica.
Modernización del ciclo DevOps con GitHub Enterprise en el sector público
Institución financiera clave en Costa Rica consolidó su estrategia DevSecOps con Nubiral, migrando a GitHub Enterprise Cloud y optimizando su seguridad.
Modernización de aplicaciones: Decisiones que redefinen la agilidad del negocio
Evolucionar sistemas legacy sin frenar la operación permite potenciar el desarrollo con IA, reducir deuda técnica, acelerar ciclos de entrega y construir software preparado para adaptarse de forma continua a las demandas del negocio.
Escalamos a entornos con miles de ítems monitoreados en forma simultánea.
Además capturamos datos de comportamiento de sistemas y aplicaciones a lo largo del tiempo, para la toma de decisiones proactivas y lograr anticipar disrupciones en los servicios de tu negocio.
Infraestructura vial con monitoreo unificado y gestión de incidentes automatizada
Una empresa del sector de transporte e infraestructura modernizó la visibilidad operativa de su infraestructura on-premise distribuida implementando Zabbix 7.0 LTS con integración nativa a InvGate Service Desk, eliminando la gestión manual de incidentes y centralizando el monitoreo de entornos Linux y Windows en una sola plataforma.
Madurez en la gestión de datos con Microsoft Azure
Uno de los principales bancos de chile utiliza los servicios más avanzados de AWS para trabajar sobre la ingesta, almacenamiento, detección y modelos predictivos de data proveniente de fuentes de inteligencia de ciberseguridad.
Observabilidad en la era de los agentes: Cómo escalar operaciones inteligentes sin perder control
La visibilidad en tiempo real es clave para supervisar sistemas autónomos, anticipar incidentes y sostener operaciones digitales cada vez más complejas.
La importancia de la observabilidad en el mundo de la tecnología
Revive el webinar donde hablamos sobre importancia de la observabilidad en el mundo de la tecnología y cómo puede ser utilizada para mejorar la eficiencia, la productividad y la satisfacción de los usuarios.
Agentic AI: ¿Aliada o enemiga de la ciberseguridad?
Esta nueva tecnología autónoma promete acelerar la innovación empresarial, pero también abre interrogantes sobre control, gobernanza y gestión del riesgo en entornos cada vez más complejos.
Agentic AI: ¿Aliada o enemiga de la ciberseguridad?
Esta nueva tecnología autónoma promete acelerar la innovación empresarial, pero también abre interrogantes sobre control, gobernanza y gestión del riesgo en entornos cada vez más complejos.
Banca sin core: Las APIs redefinen la ventaja competitiva
La agilidad y la flexibilidad en el sector financiero surgen hoy de arquitecturas abiertas capaces de vincular servicios, integrarse con ecosistemas y desplegar rápidamente nuevos canales digitales.
Observabilidad en la era de los agentes: Cómo escalar operaciones inteligentes sin perder control
La visibilidad en tiempo real es clave para supervisar sistemas autónomos, anticipar incidentes y sostener operaciones digitales cada vez más complejas.
Licencias bajo presión: La hora de replantear la arquitectura
Los aumentos de hasta 1.000% en renovaciones obligan a los equipos de TI y finanzas a evaluar si conviene seguir sosteniendo la infraestructura actual o aprovechar el momento para emprender un rediseño.
Servicios financieros en la era agentic: Modernizar sin perder escala, control ni velocidad
Claves de arquitectura, datos y estrategia para convertir iniciativas de IA en capacidades operativas reales. Un paper para equipos de tecnología y decisores del sector financiero en LATAM.
La importancia de la observabilidad en el mundo de la tecnología
Revive el webinar donde hablamos sobre importancia de la observabilidad en el mundo de la tecnología y cómo puede ser utilizada para mejorar la eficiencia, la productividad y la satisfacción de los usuarios.
Ciclo de webinars de Data, Analytics & IA | Sesión #3: El impacto de IA & Analytics en el sector de media
Revive el ciclo de 3 charlas donde hablamos sobre la utilización de estas herramientas tecnológicas y su impacto en diferentes industrias, en esta oportunidad de la mano de nuestro especialista Javier Minhondo. Quien actualmente es Business Solution Architect de Nubiral.
Connect+ es una gran herramienta para incorporar conocimientos y estar al tanto de las últimas novedades tecnológicas.
Accede a nuevos contenidos audiovisuales innovadores, de forma rápida y sencilla. ¡Explora y conoce el universo tecnológico de una manera diferente y ágil!
Sistemas de recomendación con machine learning en empresas de medios digitales
Los avances en machine learning permiten que las empresas de medios digitales mejoren sus sistemas de recomendación y optimicen la experiencia del usuario.
Innovación y tecnología se nutren mutuamente y adoptarlas ya no es una opción.
Por ello, te ayudamos a capturar toda la data interna y externa, institucionalizar la toma de decisiones a través de Business Analytics, tener procesos inteligentes y automáticos y finalmente una estrategia de inteligencia artificial para optimizar la operación y predecir lo que se viene.
Acompañamos a las organizaciones en cada etapa de su adopción de inteligencia artificial, desde la estrategia y los primeros casos de uso hasta soluciones productivas que transforman procesos, reducen costos y generan valor de negocio tangible.
Sistema de monitoreo avanzado basado en multiagentes de IA generativa que permite la toma de decisiones en tiempo real a partir del análisis continuo de datos.
Repositorio de datos que puede ser almacenado en la infraestructura de la empresa, donde con flexibilidad podemos guardar el máximo de la información que recolectamos.
Del chatbot a una interacción más real. Buscamos que cada consulta se resuelva mediante el agente, reduciendo la intervención humana, sin sacrificar precisión ni trazabilidad.
De 5% a 98%: Adopción de Copilot 365 en el sector bancario
Cómo un banco líder en Argentina convirtió miles de licencias de IA generativa en hábitos de trabajo concretos, y alcanzó sus metas de adopción en un trimestre.
Cómo una plataforma de streaming deportivo aceleró la toma de decisiones al democratizar el acceso a sus datos integrando Amazon Bedrock y Redshift directamente en Slack.
Detección temprana de fallas y predicción de merma en pozos petroleros
Cómo el análisis avanzado de datos y Machine Learning permiten anticipar el deterioro en bombas electro-sumergibles, asegurando la continuidad productiva en la industria de Oil & Gas.
Transformación de la atención comercial con IA conversacional en el sector automotriz
El despliegue de un agente conversacional RAG transformó el proceso de ventas de un grupo automotriz en México, habilitando atención continua por WhatsApp y voz, agendamiento inteligente y trazabilidad completa de datos en el CRM.
Por qué más del 90% de los proyectos de IA en banca no escala (y cómo evitarlo)
Qué obstáculos frenan la llegada a producción y por qué la infraestructura, los datos y la alineación con el negocio son mucho más importantes que el modelo.
Servicios financieros en la era agentic: Modernizar sin perder escala, control ni velocidad
Claves de arquitectura, datos y estrategia para convertir iniciativas de IA en capacidades operativas reales. Un paper para equipos de tecnología y decisores del sector financiero en LATAM.
Arquitectura informática que combina una nube privada y una pública de forma que entreguen un conjunto flexible de servicios.
Esto significa que las cargas de trabajo migran de manera fluida y transparente entre un entorno y el otro de acuerdo a las necesidades que tenga la empresa en cada momento.
Optimización operativa y escalado automático para portales de gestión académica
Cómo un grupo educativo líder modernizó la infraestructura de sus plataformas estudiantiles hacia una arquitectura de contenedores, logrando despliegues automatizados y eliminando el mantenimiento de servidores.
Automatización de operaciones, mayor seguridad y reducción de costos en la nube
Estrategia integral de Cloud Operations que permitió modernizar y encapsular aplicaciones críticas, fortaleció la seguridad, automatizó la operación y proyectó significativos ahorros.
Gobernanza Cloud: Nueva era operativa en empresa líder de Servicios Financieros
Migración integral y gestión operativa proactiva en AWS, optimizando seguridad, eficiencia y agilidad para impulsar la transformación digital en empresa líder.
Banca sin core: Las APIs redefinen la ventaja competitiva
La agilidad y la flexibilidad en el sector financiero surgen hoy de arquitecturas abiertas capaces de vincular servicios, integrarse con ecosistemas y desplegar rápidamente nuevos canales digitales.
¿Cómo asegurar ambientes de APIs? ¿Cómo utilizar las tecnologías más avanzadas sin quedar expuesto? Esto y otros temas relacionados, han sido expuestos en el presente webinar.
Desde Nubiral analizamos y dimensionamos cada proyecto de tu empresa con el fin de mejorar la eficiencia de tu infraestructura TI, diseñando soluciones flexibles de alto rendimiento basadas en la experiencia de nuestros profesionales, los últimos avances tecnológicos y las tendencias actuales de cada industria.
De la fragmentación digital a una plataforma lista para el open banking
Banco Columbia tenía los productos, la visión y la ambición de crecer digitalmente. Lo que necesitaba era una plataforma que pudiera sostener ese crecimiento sin fisuras.
Migración estratégica a GitHub Enterprise para optimizar el ciclo de desarrollo
Una de las principales plataformas financieras digitales de Colombia unificó sus flujos DevOps en GitHub, fortaleciendo la colaboración y la gobernanza tecnológica.
Modernización del ciclo DevOps con GitHub Enterprise en el sector público
Institución financiera clave en Costa Rica consolidó su estrategia DevSecOps con Nubiral, migrando a GitHub Enterprise Cloud y optimizando su seguridad.
Modernización de aplicaciones: Decisiones que redefinen la agilidad del negocio
Evolucionar sistemas legacy sin frenar la operación permite potenciar el desarrollo con IA, reducir deuda técnica, acelerar ciclos de entrega y construir software preparado para adaptarse de forma continua a las demandas del negocio.
Escalamos a entornos con miles de ítems monitoreados en forma simultánea.
Además capturamos datos de comportamiento de sistemas y aplicaciones a lo largo del tiempo, para la toma de decisiones proactivas y lograr anticipar disrupciones en los servicios de tu negocio.
Infraestructura vial con monitoreo unificado y gestión de incidentes automatizada
Una empresa del sector de transporte e infraestructura modernizó la visibilidad operativa de su infraestructura on-premise distribuida implementando Zabbix 7.0 LTS con integración nativa a InvGate Service Desk, eliminando la gestión manual de incidentes y centralizando el monitoreo de entornos Linux y Windows en una sola plataforma.
Madurez en la gestión de datos con Microsoft Azure
Uno de los principales bancos de chile utiliza los servicios más avanzados de AWS para trabajar sobre la ingesta, almacenamiento, detección y modelos predictivos de data proveniente de fuentes de inteligencia de ciberseguridad.
Observabilidad en la era de los agentes: Cómo escalar operaciones inteligentes sin perder control
La visibilidad en tiempo real es clave para supervisar sistemas autónomos, anticipar incidentes y sostener operaciones digitales cada vez más complejas.
La importancia de la observabilidad en el mundo de la tecnología
Revive el webinar donde hablamos sobre importancia de la observabilidad en el mundo de la tecnología y cómo puede ser utilizada para mejorar la eficiencia, la productividad y la satisfacción de los usuarios.
Agentic AI: ¿Aliada o enemiga de la ciberseguridad?
Esta nueva tecnología autónoma promete acelerar la innovación empresarial, pero también abre interrogantes sobre control, gobernanza y gestión del riesgo en entornos cada vez más complejos.
Agentic AI: ¿Aliada o enemiga de la ciberseguridad?
Esta nueva tecnología autónoma promete acelerar la innovación empresarial, pero también abre interrogantes sobre control, gobernanza y gestión del riesgo en entornos cada vez más complejos.
Banca sin core: Las APIs redefinen la ventaja competitiva
La agilidad y la flexibilidad en el sector financiero surgen hoy de arquitecturas abiertas capaces de vincular servicios, integrarse con ecosistemas y desplegar rápidamente nuevos canales digitales.
Observabilidad en la era de los agentes: Cómo escalar operaciones inteligentes sin perder control
La visibilidad en tiempo real es clave para supervisar sistemas autónomos, anticipar incidentes y sostener operaciones digitales cada vez más complejas.
Licencias bajo presión: La hora de replantear la arquitectura
Los aumentos de hasta 1.000% en renovaciones obligan a los equipos de TI y finanzas a evaluar si conviene seguir sosteniendo la infraestructura actual o aprovechar el momento para emprender un rediseño.
Servicios financieros en la era agentic: Modernizar sin perder escala, control ni velocidad
Claves de arquitectura, datos y estrategia para convertir iniciativas de IA en capacidades operativas reales. Un paper para equipos de tecnología y decisores del sector financiero en LATAM.
La importancia de la observabilidad en el mundo de la tecnología
Revive el webinar donde hablamos sobre importancia de la observabilidad en el mundo de la tecnología y cómo puede ser utilizada para mejorar la eficiencia, la productividad y la satisfacción de los usuarios.
Ciclo de webinars de Data, Analytics & IA | Sesión #3: El impacto de IA & Analytics en el sector de media
Revive el ciclo de 3 charlas donde hablamos sobre la utilización de estas herramientas tecnológicas y su impacto en diferentes industrias, en esta oportunidad de la mano de nuestro especialista Javier Minhondo. Quien actualmente es Business Solution Architect de Nubiral.
Connect+ es una gran herramienta para incorporar conocimientos y estar al tanto de las últimas novedades tecnológicas.
Accede a nuevos contenidos audiovisuales innovadores, de forma rápida y sencilla. ¡Explora y conoce el universo tecnológico de una manera diferente y ágil!
Sistemas de recomendación con machine learning en empresas de medios digitales
Los avances en machine learning permiten que las empresas de medios digitales mejoren sus sistemas de recomendación y optimicen la experiencia del usuario.
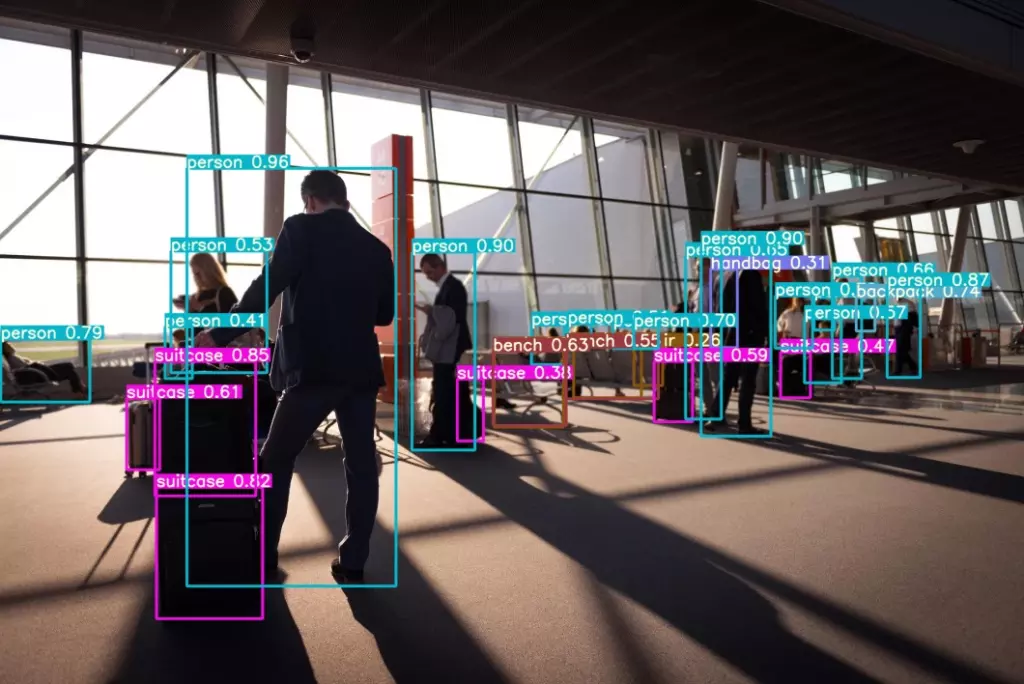
Computer vision models are always expected to provide the most accurate results. For that, it is necessary to train them previously with the largest possible dataset.
However, in many cases, the amount of data available is not sufficient. The concept of data augmentation in images aims precisely at creating synthetic data to be completed when needed.
Let’s suppose that an application needs to identify the deterioration in a roof. It is difficult to find an image bank in that organization that shows all possible levels and types of deterioration. The solution: create the eventual gaps. This is just one example. There are an enormous number of situations in which this same concept is applied.
A review of the computer vision concept
It is worth remembering that computer vision is a technology that allows machines to analyze digital photos and videos. The objective? To extract meaning from them.
To achieve that result, it successfully combines image processing with machine learning and advanced analytics.
Thus, it is able to recognize objects or faces, identify patterns or anomalies or understand medical images, among many other applications. Including many of those we design in our Data & Innovation area.
Its use is increasingly popular in industries such as healthcare, entertainment and digital media, manufacturing, agribusiness and, especially, security and video surveillance.
In all cases, the purpose is the same: to take advantage of images to turn them into actionable information for the business.
Uses of data augmentation in images
Among the reasons for generating synthetic data to train computer vision models are the increase in both the size of the data set and its diversity.
Returning to the previous example, there could be a hundred photos available on the deteriorated roof, but all with a similar or identical level. With data augmentation, this base is also expanded.
In the same approach, the creation of synthetic data ensures that all possible conditions and scenarios are covered, with no room for error or omissions.
Another use is to speed up labeling, since it can be performed automatically on the generated data. This is not always possible or straightforward on a real data set.
Finally, there is a reason linked to data security and privacy. With synthetic data, the real data is guaranteed to be protected. This applies particularly to cases where confidential information is involved.
Image data augmentation techniques
There are several data augmentation techniques in images. Some of the most tested ones are:
Flipping: It consists of rotating images both horizontally and vertically. It is estimated that with this technique it is possible to double or quadruple the original amount of data.
Rotation: Consists of rotating the image at different angles, taking care at all times that the original dimensions are preserved at the end of the operation. Again, the increase factor in the amount of data is estimated to be double to quadruple, although it could be even higher.
Scaling: This consists of changing the scale of the image. It can be done outward (the resulting image will be larger than the original). Also inward (smaller). The magnification factor depends on the amount of scaling done on the same image.
Random cropping: Consists in taking a random sample of a section of the original image. As with scaling, the magnification factor is arbitrary.
Translation: Involves moving the image along the X-axis or Y-axis, or both, from its original position. Again, the magnification factor is arbitrary and will depend on the number of translations performed for each image.
Technologies available in AWS
AWS has Amazon Bedrock, which is a managed service that allows us to access generative models capable of generating synthetic data from a set of real data and prompts.
Amazon Bedrock is a managed service that offers access to a wide selection of FMs (foundational models), which are models capable of generating new and original content from an input stimulus. These FMs have the particularity that they are high-performance models provided by different leading AI companies (as is AWS).
Amazon Rekognition is a managed service that enables the development of Computer Vision capabilities and models. Particularly with Rekognition, custom labels can be made by which various data augmentations are performed for model training, such as random image cropping, color fluctuation and random Gaussian noises. Instead of employing thousands of images, you can upload only a small set of training images (usually a few hundred less) specific to your use case to the easy-to-use console.
Conclusions
Computer vision is a branch of artificial intelligence (AI) that brings great value to the business. It extracts actionable information from images and videos.
Data augmentation strategies allow organizations to generate synthetic datasets to optimize the training of computer vision models and obtain the best possible results.
It solves both the need for quantity of data and the need for diversity or labeling. Paradoxically, success will be in sight.
Does your organization need professional help to drive initiatives based on computer vision? At Nubiral, we have the experience, the experts and the knowledge to lead you on this journey. We look forward to hearing from you: Schedule your meeting!
Por qué más del 90% de los proyectos de IA en banca no escala (y cómo evitarlo)
Qué obstáculos frenan la llegada a producción y por qué la infraestructura, los datos y la alineación con el negocio son mucho más importantes que el modelo.
Decisiones tecnológicas que deben tomarse en 2026: Las preguntas fundamentales
Las decisiones en cloud e IA no admiten más postergaciones: cómo modernizar, escalar y optimizar hoy define la capacidad de innovar, competir y crecer de forma sostenida en los próximos años.
Tres fuerzas que reconfiguran la agenda tecnológica: IA, cloud y seguridad
Automatización inteligente, optimización de costos en cloud y seguridad proactiva: tres ejes que se articulan para transformar la operación tecnológica con impacto directo en productividad, costos y resiliencia.
Por qué más del 90% de los proyectos de IA en banca no escala (y cómo evitarlo)
Qué obstáculos frenan la llegada a producción y por qué la infraestructura, los datos y la alineación con el negocio son mucho más importantes que el modelo.
Servicios financieros en la era agentic: Modernizar sin perder escala, control ni velocidad
Claves de arquitectura, datos y estrategia para convertir iniciativas de IA en capacidades operativas reales. Un paper para equipos de tecnología y decisores del sector financiero en LATAM.