Data & Innovation • Telecommunications • AWS
Arquitectura META de Datos en la Nube
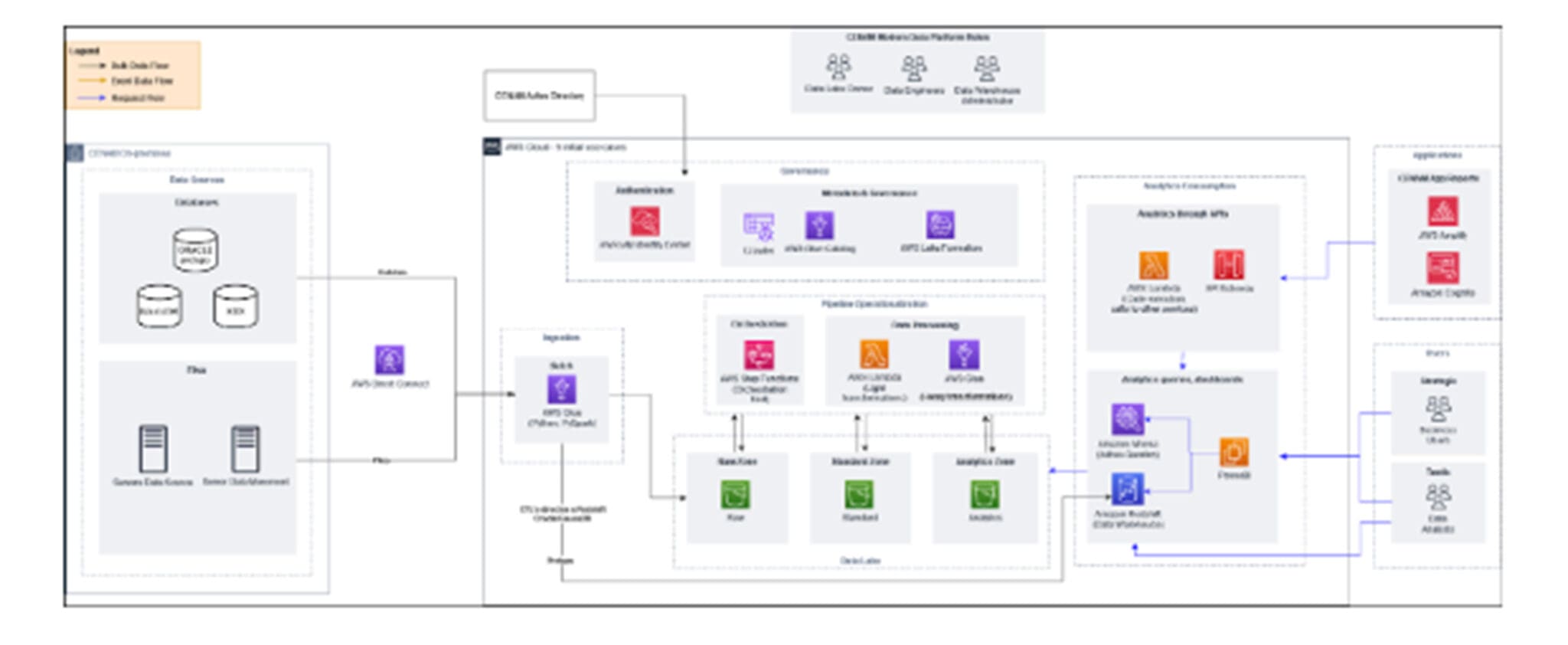
Implementación de la primera arquitectura META de datos en la nube de AWS con asociación a un conjunto de casos de uso.
Antecedentes y Requerimientos
El equipo de una importante empresa de telecomunicaciones, después de un riguroso proceso de evaluación tecnológica, decidió implementar la primera arquitectura META de datos en la nube de AWS.
Esta decisión se tomó con el objetivo de asociarla a un conjunto de casos de uso seleccionados por el equipo interno, permitiendo así formalizar y disponibilizar los flujos de datos dentro del marco de la gestión, el gobierno, y la entrega eficiente de los datos.

Fases del proyecto
Dentro de la fase de implementación de la arquitectura META, se consideró la habilitación de AWS Direct Connect y la integración con las distintas nubes, datalake, o centros de datos on-premise.
Primera etapa
Implementación de Direct Connect
Segunda etapa
Integración con Distintas Nubes, Datalake y Centros de Datos On-Premise
Implementación y resultados obtenidos
La fase inicial del proyecto contempló una arquitectura tipo “Lake House” diseñada para cubrir varios casos de uso críticos, incluyendo:
-
- Aplicativo de autoservicio de reportería.
-
- Capa analítica para el procesamiento de servicios pospago y fijo, entre otros.
El objetivo principal de la primera fase fue obtener resultados de manera rápida, priorizando los casos de uso mencionados anteriormente. Esto se logró mediante la implementación de estrategias de DataOps, que permitieron la orquestación estandarizada de herramientas, código e infraestructura, asegurando una entrega rápida de datos de alta calidad.
Para el procesamiento de los cubos de postpago y fijo, se consideraron todos los países que abarca el cliente.
Se replicaron los flujos ya realizados con prepago sobre tecnología AWS para crear los tableros de BI necesarios, visualizando así toda la operación del cliente. Los nuevos flujos de cubos de postpago y fijo se acompañaron con la optimización de los modelos actuales una vez configurados los pipelines sobre AWS.
Se aplicó el mismo enfoque para los flujos de procesamiento de servicios de valor agregado, reportes operativos de Pretups, flujos de movilidad y mediación/interconexión. Para los flujos de postpago y fijo, se incluyeron componentes como altas, bajas, parque, ciclo de facturación y tráfico para el cubo postpago, y altas, bajas e ingresos para el cubo fijo. Estos flujos se disponibilizaron y configuraron en los servicios de AWS, dejando la optimización de los modelos para una etapa posterior. Además, se integró la solución con los recursos ya existentes en la nube, como la capa de networking y compliance.
En cuanto a los flujos de reportes operativos de Pretup, modelo de movilidad, reportes de mediación/interconexión y el flujo de D10, se contempló la exploración, el entendimiento, los flujos y su adecuación al entorno de AWS, desde la capa del data lake hasta el almacenamiento dentro del data warehouse para ser consumido.

Aplicativo de Autoservicio de Reportería
El proyecto también incluyó el desarrollo de un portal de autoservicio web hospedado en la nube de AWS, cuyo objetivo fue automatizar diversos requerimientos de los clientes internos del cliente.
Este portal permite la generación de reportes basados en un conjunto de filtros, devolviendo datos ordenados por un periodo de tiempo seleccionado.

Funcionalidades del Portal
Autenticación: El portal cuenta con autenticación para usuarios seleccionados.
Búsqueda de Transacciones: Permite búsquedas por diversos criterios, como nombre de abonado, número de teléfono, número de IMEI, número de identificación (DPI), número de NIT, y fecha de transacción.
Generación de Reportes: Basados en los datos filtrados según fechas seleccionadas.
Guardado de Reportes: Permite guardar las consultas generadas.
Descarga de Información: Los usuarios pueden descargar la información en formato compatible (CSV) o enviar la petición de descarga por correo electrónico.
Auditoría: Incluye el almacenamiento de las peticiones realizadas en una base de datos persistente, cumpliendo con regulaciones.
Conclusiones
Durante la ejecución de este proyecto, Nubiral demostró la capacidad de desarrollar una arquitectura de datos que permitiese al cliente atender diversos desafíos que las distintas áreas de negocio presentaban. La primera prioridad fue garantizar la integridad de los datos de forma segura, para lo cual AWS Direct Connect permitió establecer un canal de comunicación seguro y con conexiones dedicadas.
El cliente cuenta con una cartera importante de fuentes de datos interdependientes que se ejecutan en sus centros de datos locales o en distintas nubes públicas.
Durante mucho tiempo, han querido trasladar estas cargas de trabajo a la nube pública. Las pruebas fueron cruciales porque, al llevar dichas cargas a la nube, era necesario garantizar una experiencia perfecta para los usuarios finales (usuarios de datos de negocio).
Las zonas locales de AWS resolvieron este problema al proporcionar comunicación de latencia ultrabaja entre los distintos sistemas en la zona local y las instalaciones locales. Esto permitió migrar nuevas fuentes de información de forma incremental, simplificando drásticamente las migraciones y reduciendo al mismo tiempo cualquier riesgo empresarial con implementaciones híbridas continuas.