




Guías Técnicas
Cómo agilizar los procesos ETL con Microsoft Fabric
El poder de Microsoft Fabric permite a los analistas, ingenieros y científicos de datos realizar ETLs con una curva de aprendizaje menor.
- 1. Introducción
- 2. Lo que hay que saber sobre Fabric en procesos ETL
- 3. ¿Cómo agilizar los procesos ETL con Microsoft Fabric?
- 4. ¿Cómo implementar Microsoft Fabric?
- 5. Conclusiones
1. Introducción
Los datos se multiplican en volumen, en orígenes, en formato. La capacidad de las empresas de combinarlos, gestionarlos, almacenarlos y accederlos de manera adecuada hace la diferencia en este contexto de negocios digitales.
El proceso de “extracción, transformación y carga” (ETL, por sus siglas en inglés) permite afrontar este desafío. Es un proceso que se usa para recopilar datos de varios orígenes, transformarlos según las reglas del negocio y cargarlos en un almacén de destino. En medio, los datos se filtran, se ordenan, se combinan, se limpian y se validan.
Esta guía explica cómo Microsoft Fabric ayuda a agilizar los procesos ETL, un paso clave para las empresas que quieran convertirse en una compañía data driven.
2. Lo que hay que saber sobre Fabric en procesos ETL
Los ETLs en Microsoft Fabric se apoyan y combinan tecnologías ya conocidas como DataFactory de Azure y PowerQuery de PowerBI. Esto significa que si el responsable tiene experiencia en alguna de ellas, el pasaje a Fabric debería ser inmediato.
Microsoft Fabric hace énfasis en las mencionadas herramientas low code/no code (de baja o nula codificación). Esto significa que, además, brinda herramientas visuales que hacen que todo sea más accesible. Dicho de otra manera, los analistas de datos pueden realizar ETLs más complejos con una curva de aprendizaje menor. Esta facilidad de uso amplía la posibilidad de que estas tareas las desempeñen ya no sólo los ingenieros de datos, sino también otros roles, como analistas de datos y científicos de datos.
Por otra parte, Microsoft Fabric cuenta con una amplia gama de conectores con diferentes herramientas y tecnologías (Incluso las que no son cloud o de fabricantes diferentes de Microsoft). Esto habilita a lograr extracciones de una extensa lista de orígenes de datos.
3. ¿Cómo agilizar los procesos ETL con Microsoft Fabric?
Más allá de lo mencionado, Microsoft Fabric incorpora varias funcionalidades y facilidades para que sea más simple y más accesible el desarrollo de ETLs. Esto incluye:
– Más de 200 conectores a una gran variedad de fuentes de datos tanto on premise como SaaS y otros proveedores de nube.
– Fabric Copilot como herramienta de asistencia en la generación de ETL con las herramientas visuales e incluso en la generación de código, si el caso fuese necesario.
– Herramientas visuales para desarrollo de queries (consultas / transformaciones sobre la información recopilada).
– Data Activator, herramienta no-code para ejecutar acciones cuando ciertos eventos ocurren. Por ejemplo, cuando establecemos una métrica sobre una campaña de marketing como las ventas de un producto, si está por debajo de un límite preestablecido podemos detonar acciones (enviar correos, dar un aviso por Microsoft Teams y muchas más).
– Templates de soluciones de Fabric para industrias específicas como Fabric for Retail.
4. ¿Cómo implementar Microsoft Fabric?
La implementación de Microsoft Fabric debe comenzar por cuál es la pregunta de negocios que queremos responder. Una vez identificada, para responderla, debemos trabajar hacia atrás para entender los modelos de datos, las transformaciones, el procesamiento y las fuentes de datos a considerar.
El siguiente paso es definir si el proceso de ingesta será en batch (es decir, en unas ventanas de tiempo preestablecidas) o si se requiere un tratamiento especial real time o near real time. Luego, mapear el tipo de información a extraer, identificar que tipo de conectividad que necesitamos dependiendo de todo lo anterior. Por último, definir la tecnología de ETL (nos concentraremos en Dataflow y Pipeline).
Los pasos de la implementación son:
Trazar los objetivos y alcance del proyecto
Es un paso fundamental en la implementación de cualquier iniciativa en una organización, incluyendo por supuesto la de Fabric.
Implica una identificación de los logros esperados y de los límites del proyecto. Entre otras cosas, debe decidirse:
– Cuáles son los datos a mover/extraer.
– Con qué frecuencia se actualizan.
– Qué sistemas dependen de ellos.
Así, se obtiene un contexto que debe combinarse con otros aspectos, como el presupuesto asignado, los beneficios anticipados y los posibles riesgos de la implementación.
También es esencial que todas las partes interesadas comprendan los objetivos y los límites del proyecto. La comunicación transparente y la alineación efectiva con los involucrados garantizan el respaldo necesario a lo largo del proceso.
Configuración inicial
Microsoft Fabric no obliga a lidiar con configuraciones iniciales complejas.
Parte de su secreto reside en su simpleza. Un par de clics bastan para comenzar a aprovechar al máximo esta potente herramienta de análisis y gestión de datos.
Para habilitar las funcionalidades es necesario cumplir con dos prerrequisitos:
– Un inquilino o tenant a nivel organizacional en el entorno de Microsoft.
– Algún rol de administrador en Microsoft 365, Power Platform o Fabric.
Luego, el proceso de configuración inicial es sencillo. Consiste simplemente en acceder a la configuración del inquilino (tenant settings) y habilitar Microsoft Fabric para toda la organización o para un grupo específico de usuarios.
Orígenes de datos
Este paso permite comprender la complejidad de los datos que deben transferirse entre entornos de nube. Así, garantiza una migración exitosa.
Para llevar a cabo esta tarea de manera efectiva hay que llevar a cabo:
– Inventario de fuentes de datos de la infraestructura actual. Incluye bases de datos, sistemas de archivos, aplicaciones, servicios web y cualquier otro repositorio de datos.
– Clasificación de datos. Se realiza en función de su importancia y criticidad para el negocio. Algunos pueden ser esenciales y otros, menos relevantes. Ayuda a priorizar el orden en el que se involucrarán los datos a los procesos de datos.
– Análisis de dependencias entre diferentes conjuntos de datos y aplicaciones. Algunos pueden ser interdependientes y deben migrarse juntos para evitar problemas de coherencia.
– Evaluación de calidad de datos en cada fuente. Incluye la precisión, la integridad y la consistencia de los datos. Los de baja calidad pueden requerir limpieza antes de poder ser usados.
– Mapeo de datos detallado que indica de dónde provienen, cómo se utilizan y dónde deben residir en el entorno multicloud de destino (En este caso, Microsoft Fabric). Incluye definir estructuras de datos, formatos y esquemas.
Dataflow vs Pipeline
La ingestión y la preparación de datos son fundamentales para las empresas que quieran basar sus decisiones en datos.
Microsoft Fabric ofrece dos poderosas herramientas: Pipelines y Dataflows, que simplifican estos procesos cruciales y brindan ventajas excepcionales al unificar datos de múltiples nubes.
Ambas permiten ingresar información desde diferentes nubes (Azure, AWS, GCP, entre otras) con conectores nativos que se configuran con unos pocos parámetros básicos. Es tan simple que hasta pueden hacerlo usuarios sin experiencia técnica.
Pipelines constituye una solución completa y versátil para la ingestión de datos. Conectar una variedad de fuentes, desde bases de datos locales hasta nubes y aplicaciones de terceros, por lo que es ideal para consolidar datos dispersos.
Dataflow proveniente de Power BI, por su parte, facilita la preparación de datos de manera ágil y potente para la etapa de transformación. Permite crear procesos ETL en una interfaz intuitiva de tipo “arrastrar y soltar”. También permite aplicar filtros, limpiar datos, realizar agregaciones y combinar múltiples fuentes sin necesidad de codificación compleja.
Dataflow tiene como ventaja la reutilización. Los flujos de trabajo de transformación creados pueden ser compartidos y utilizados en diversos procesos posteriores como lo pueden ser los informes y paneles de Power BI (dentro de Microsoft Fabric). Esto ahorra tiempo y asegura la coherencia en los análisis.
En cualquiera de los casos, los datos van a ser tratados, depurados y transformados. También se les aplicarán las reglas del negocio para su posterior explotación. En los casos en que sea posible, se incluirán transformaciones que permitan por sí mismas agregar valor al negocio.
Almacenamiento adecuado
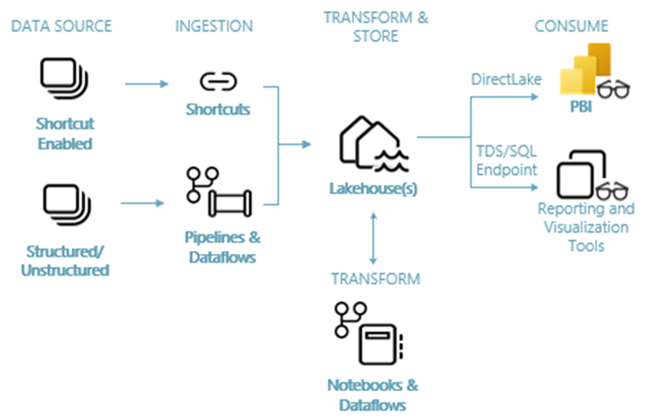
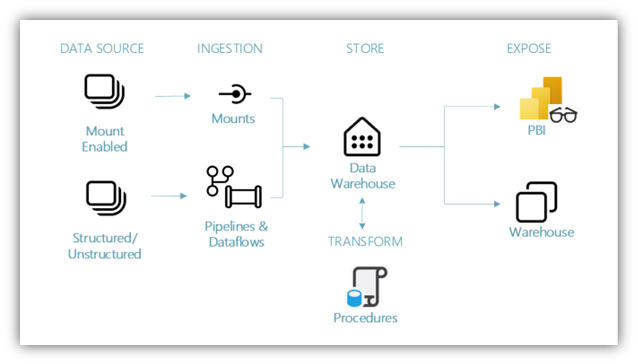
Dependiendo de los requerimientos iniciales, del tipo de datos y de las consultas a realizar, podremos optar entre un Data Warehouse o un Lakehouse (disponibles ambos en Microsoft Fabric).
5. Conclusiones
Microsoft Fabric ofrece numerosas ventajas para agilizar los procesos ETL:
– Aporta una experiencia end to end para la realización de las ETL. Esto implica que se simplifica la administración de plataformas para esta tarea tan importante.
– Se apoya en tecnologías reconocidas en el mercado, por lo que hay muchos usuarios con experiencia en algunas de ellas, lo que facilita la transición hacia Fabric.
– Incluye numerosas herramientas low code/no code para hacer reducir la curva de aprendizaje de los analistas de datos que realizan ETL, aún cuando se trate de los más complejos.
– Ofrece conectores para lograr extracciones de una extensa lista de orígenes de datos.
– Brinda el asistente de generador de código y flujos Fabric Copilot y templates para industrias específicas.
– Su implementación es sencilla y no genera fricciones ni complicaciones.
– De esta manera, garantiza la obtención de valor de los datos.
En Nubiral tenemos los especialistas, la experiencia y el conocimiento para ayudarte a tener éxito en este proceso. ¡Agenda tu reunión!
Guía técnica: Cómo agilizar los procesos ETL con Microsoft Fabric
- Introducción
Los datos se multiplican en volumen, en orígenes, en formato. La capacidad de las empresas de combinarlos, gestionarlos, almacenarlos y accederlos de manera adecuada hace la diferencia en este contexto de negocios digitales.
El proceso de “extracción, transformación y carga” (ETL, por sus siglas en inglés) permite afrontar este desafío. Es un proceso que se usa para recopilar datos de varios orígenes, transformarlos según las reglas del negocio y cargarlos en un almacén de destino. En medio, los datos se filtran, se ordenan, se combinan, se limpian y se validan.
Esta guía explica cómo Microsoft Fabric ayuda a agilizar los procesos ETL, un paso clave para las empresas que quieran convertirse en una compañía data driven.
- Lo que hay que saber sobre Fabric en procesos ETL
Los ETLs en Microsoft Fabric se apoyan y combinan tecnologías ya conocidas como DataFactory de Azure y PowerQuery de PowerBI. Esto significa que si el responsable tiene experiencia en alguna de ellas, el pasaje a Fabric debería ser inmediato.
Microsoft Fabric hace énfasis en las mencionadas herramientas low code/no code (de baja o nula codificación). Esto significa que, además, brinda herramientas visuales que hacen que todo sea más accesible. Dicho de otra manera, los analistas de datos pueden realizar ETLs más complejos con una curva de aprendizaje menor. Esta facilidad de uso amplía la posibilidad de que estas tareas las desempeñen ya no sólo los ingenieros de datos, sino también otros roles, como analistas de datos y científicos de datos.
Por otra parte, Microsoft Fabric cuenta con una amplia gama de conectores con diferentes herramientas y tecnologías (Incluso las que no son cloud o de fabricantes diferentes de Microsoft). Esto habilita a lograr extracciones de una extensa lista de orígenes de datos.
- ¿Cómo agilizar los procesos ETL con Microsoft Fabric?
Más allá de lo mencionado, Microsoft Fabric incorpora varias funcionalidades y facilidades para que sea más simple y más accesible el desarrollo de ETLs. Esto incluye:
– Más de 200 conectores a una gran variedad de fuentes de datos tanto on premise como SaaS y otros proveedores de nube.
– Fabric Copilot como herramienta de asistencia en la generación de ETL con las herramientas visuales e incluso en la generación de código, si el caso fuese necesario.
– Herramientas visuales para desarrollo de queries (consultas / transformaciones sobre la información recopilada).
– Data Activator, herramienta no-code para ejecutar acciones cuando ciertos eventos ocurren. Por ejemplo, cuando establecemos una métrica sobre una campaña de marketing como las ventas de un producto, si está por debajo de un límite preestablecido podemos detonar acciones (enviar correos, dar un aviso por Microsoft Teams y muchas más).
– Templates de soluciones de Fabric para industrias específicas como Fabric for Retail.
- ¿Cómo implementar Microsoft Fabric?
La implementación de Microsoft Fabric debe comenzar por cuál es la pregunta de negocios que queremos responder. Una vez identificada, para responderla, debemos trabajar hacia atrás para entender los modelos de datos, las transformaciones, el procesamiento y las fuentes de datos a considerar.
El siguiente paso es definir si el proceso de ingesta será en batch (es decir, en unas ventanas de tiempo preestablecidas) o si se requiere un tratamiento especial real time o near real time. Luego, mapear el tipo de información a extraer, identificar que tipo de conectividad que necesitamos dependiendo de todo lo anterior. Por último, definir la tecnología de ETL (nos concentraremos en Dataflow y Pipeline).
Los pasos de la implementación son:
Trazar los objetivos y alcance del proyecto
Es un paso fundamental en la implementación de cualquier iniciativa en una organización, incluyendo por supuesto la de Fabric.
Implica una identificación de los logros esperados y de los límites del proyecto. Entre otras cosas, debe decidirse:
– Cuáles son los datos a mover/extraer.
– Con qué frecuencia se actualizan.
– Qué sistemas dependen de ellos.
Así, se obtiene un contexto que debe combinarse con otros aspectos, como el presupuesto asignado, los beneficios anticipados y los posibles riesgos de la implementación.
También es esencial que todas las partes interesadas comprendan los objetivos y los límites del proyecto. La comunicación transparente y la alineación efectiva con los involucrados garantizan el respaldo necesario a lo largo del proceso.
Configuración inicial
Microsoft Fabric no obliga a lidiar con configuraciones iniciales complejas.
Parte de su secreto reside en su simpleza. Un par de clics bastan para comenzar a aprovechar al máximo esta potente herramienta de análisis y gestión de datos.
Para habilitar las funcionalidades es necesario cumplir con dos prerrequisitos:
– Un inquilino o tenant a nivel organizacional en el entorno de Microsoft.
– Algún rol de administrador en Microsoft 365, Power Platform o Fabric.
Luego, el proceso de configuración inicial es sencillo. Consiste simplemente en acceder a la configuración del inquilino (tenant settings) y habilitar Microsoft Fabric para toda la organización o para un grupo específico de usuarios.
Orígenes de datos
Este paso permite comprender la complejidad de los datos que deben transferirse entre entornos de nube. Así, garantiza una migración exitosa.
Para llevar a cabo esta tarea de manera efectiva hay que llevar a cabo:
– Inventario de fuentes de datos de la infraestructura actual. Incluye bases de datos, sistemas de archivos, aplicaciones, servicios web y cualquier otro repositorio de datos.
– Clasificación de datos. Se realiza en función de su importancia y criticidad para el negocio. Algunos pueden ser esenciales y otros, menos relevantes. Ayuda a priorizar el orden en el que se involucrarán los datos a los procesos de datos.
– Análisis de dependencias entre diferentes conjuntos de datos y aplicaciones. Algunos pueden ser interdependientes y deben migrarse juntos para evitar problemas de coherencia.
– Evaluación de calidad de datos en cada fuente. Incluye la precisión, la integridad y la consistencia de los datos. Los de baja calidad pueden requerir limpieza antes de poder ser usados.
– Mapeo de datos detallado que indica de dónde provienen, cómo se utilizan y dónde deben residir en el entorno multicloud de destino (En este caso, Microsoft Fabric). Incluye definir estructuras de datos, formatos y esquemas.
Dataflow vs Pipeline
La ingestión y la preparación de datos son fundamentales para las empresas que quieran basar sus decisiones en datos.
Microsoft Fabric ofrece dos poderosas herramientas: Pipelines y Dataflows, que simplifican estos procesos cruciales y brindan ventajas excepcionales al unificar datos de múltiples nubes.
Ambas permiten ingresar información desde diferentes nubes (Azure, AWS, GCP, entre otras) con conectores nativos que se configuran con unos pocos parámetros básicos. Es tan simple que hasta pueden hacerlo usuarios sin experiencia técnica.
Pipelines constituye una solución completa y versátil para la ingestión de datos. Conectar una variedad de fuentes, desde bases de datos locales hasta nubes y aplicaciones de terceros, por lo que es ideal para consolidar datos dispersos.
Dataflow proveniente de Power BI, por su parte, facilita la preparación de datos de manera ágil y potente para la etapa de transformación. Permite crear procesos ETL en una interfaz intuitiva de tipo “arrastrar y soltar”. También permite aplicar filtros, limpiar datos, realizar agregaciones y combinar múltiples fuentes sin necesidad de codificación compleja.
Dataflow tiene como ventaja la reutilización. Los flujos de trabajo de transformación creados pueden ser compartidos y utilizados en diversos procesos posteriores como lo pueden ser los informes y paneles de Power BI (dentro de Microsoft Fabric). Esto ahorra tiempo y asegura la coherencia en los análisis.
En cualquiera de los casos, los datos van a ser tratados, depurados y transformados. También se les aplicarán las reglas del negocio para su posterior explotación. En los casos en que sea posible, se incluirán transformaciones que permitan por sí mismas agregar valor al negocio.
Almacenamiento adecuado
Dependiendo de los requerimientos iniciales, del tipo de datos y de las consultas a realizar, podremos optar entre un Data Warehouse o un Lakehouse (disponibles ambos en Microsoft Fabric)
Conclusiones:
Microsoft Fabric ofrece numerosas ventajas para agilizar los procesos ETL:
– Aporta una experiencia end to end para la realización de las ETL. Esto implica que se simplifica la administración de plataformas para esta tarea tan importante.
– Se apoya en tecnologías reconocidas en el mercado, por lo que hay muchos usuarios con experiencia en algunas de ellas, lo que facilita la transición hacia Fabric.
– Incluye numerosas herramientas low code/no code para hacer reducir la curva de aprendizaje de los analistas de datos que realizan ETL, aún cuando se trate de los más complejos.
– Ofrece conectores para lograr extracciones de una extensa lista de orígenes de datos.
– Brinda el asistente de generador de código y flujos Fabric Copilot y templates para industrias específicas.
– Su implementación es sencilla y no genera fricciones ni complicaciones.
– De esta manera, garantiza la obtención de valor de los datos.
En Nubiral tenemos los especialistas, la experiencia y el conocimiento para ayudarte a tener éxito en este proceso. ¡Agenda tu reunión!