Innovación y tecnología se nutren mutuamente y adoptarlas ya no es una opción.
Por ello, te ayudamos a capturar toda la data interna y externa, institucionalizar la toma de decisiones a través de Business Analytics, tener procesos inteligentes y automáticos y finalmente una estrategia de inteligencia artificial para optimizar la operación y predecir lo que se viene.
Acompañamos a las organizaciones en cada etapa de su adopción de inteligencia artificial, desde la estrategia y los primeros casos de uso hasta soluciones productivas que transforman procesos, reducen costos y generan valor de negocio tangible.
Sistema de monitoreo avanzado basado en multiagentes de IA generativa que permite la toma de decisiones en tiempo real a partir del análisis continuo de datos.
Repositorio de datos que puede ser almacenado en la infraestructura de la empresa, donde con flexibilidad podemos guardar el máximo de la información que recolectamos.
Del chatbot a una interacción más real. Buscamos que cada consulta se resuelva mediante el agente, reduciendo la intervención humana, sin sacrificar precisión ni trazabilidad.
De 5% a 98%: Adopción de Copilot 365 en el sector bancario
Cómo un banco líder en Argentina convirtió miles de licencias de IA generativa en hábitos de trabajo concretos, y alcanzó sus metas de adopción en un trimestre.
Cómo una plataforma de streaming deportivo aceleró la toma de decisiones al democratizar el acceso a sus datos integrando Amazon Bedrock y Redshift directamente en Slack.
Detección temprana de fallas y predicción de merma en pozos petroleros
Cómo el análisis avanzado de datos y Machine Learning permiten anticipar el deterioro en bombas electro-sumergibles, asegurando la continuidad productiva en la industria de Oil & Gas.
Transformación de la atención comercial con IA conversacional en el sector automotriz
El despliegue de un agente conversacional RAG transformó el proceso de ventas de un grupo automotriz en México, habilitando atención continua por WhatsApp y voz, agendamiento inteligente y trazabilidad completa de datos en el CRM.
Por qué más del 90% de los proyectos de IA en banca no escala (y cómo evitarlo)
Qué obstáculos frenan la llegada a producción y por qué la infraestructura, los datos y la alineación con el negocio son mucho más importantes que el modelo.
Servicios financieros en la era agentic: Modernizar sin perder escala, control ni velocidad
Claves de arquitectura, datos y estrategia para convertir iniciativas de IA en capacidades operativas reales. Un paper para equipos de tecnología y decisores del sector financiero en LATAM.
Arquitectura informática que combina una nube privada y una pública de forma que entreguen un conjunto flexible de servicios.
Esto significa que las cargas de trabajo migran de manera fluida y transparente entre un entorno y el otro de acuerdo a las necesidades que tenga la empresa en cada momento.
Optimización operativa y escalado automático para portales de gestión académica
Cómo un grupo educativo líder modernizó la infraestructura de sus plataformas estudiantiles hacia una arquitectura de contenedores, logrando despliegues automatizados y eliminando el mantenimiento de servidores.
Automatización de operaciones, mayor seguridad y reducción de costos en la nube
Estrategia integral de Cloud Operations que permitió modernizar y encapsular aplicaciones críticas, fortaleció la seguridad, automatizó la operación y proyectó significativos ahorros.
Gobernanza Cloud: Nueva era operativa en empresa líder de Servicios Financieros
Migración integral y gestión operativa proactiva en AWS, optimizando seguridad, eficiencia y agilidad para impulsar la transformación digital en empresa líder.
Banca sin core: Las APIs redefinen la ventaja competitiva
La agilidad y la flexibilidad en el sector financiero surgen hoy de arquitecturas abiertas capaces de vincular servicios, integrarse con ecosistemas y desplegar rápidamente nuevos canales digitales.
¿Cómo asegurar ambientes de APIs? ¿Cómo utilizar las tecnologías más avanzadas sin quedar expuesto? Esto y otros temas relacionados, han sido expuestos en el presente webinar.
Desde Nubiral analizamos y dimensionamos cada proyecto de tu empresa con el fin de mejorar la eficiencia de tu infraestructura TI, diseñando soluciones flexibles de alto rendimiento basadas en la experiencia de nuestros profesionales, los últimos avances tecnológicos y las tendencias actuales de cada industria.
De la fragmentación digital a una plataforma lista para el open banking
Banco Columbia tenía los productos, la visión y la ambición de crecer digitalmente. Lo que necesitaba era una plataforma que pudiera sostener ese crecimiento sin fisuras.
Migración estratégica a GitHub Enterprise para optimizar el ciclo de desarrollo
Una de las principales plataformas financieras digitales de Colombia unificó sus flujos DevOps en GitHub, fortaleciendo la colaboración y la gobernanza tecnológica.
Modernización del ciclo DevOps con GitHub Enterprise en el sector público
Institución financiera clave en Costa Rica consolidó su estrategia DevSecOps con Nubiral, migrando a GitHub Enterprise Cloud y optimizando su seguridad.
Modernización de aplicaciones: Decisiones que redefinen la agilidad del negocio
Evolucionar sistemas legacy sin frenar la operación permite potenciar el desarrollo con IA, reducir deuda técnica, acelerar ciclos de entrega y construir software preparado para adaptarse de forma continua a las demandas del negocio.
Escalamos a entornos con miles de ítems monitoreados en forma simultánea.
Además capturamos datos de comportamiento de sistemas y aplicaciones a lo largo del tiempo, para la toma de decisiones proactivas y lograr anticipar disrupciones en los servicios de tu negocio.
Infraestructura vial con monitoreo unificado y gestión de incidentes automatizada
Una empresa del sector de transporte e infraestructura modernizó la visibilidad operativa de su infraestructura on-premise distribuida implementando Zabbix 7.0 LTS con integración nativa a InvGate Service Desk, eliminando la gestión manual de incidentes y centralizando el monitoreo de entornos Linux y Windows en una sola plataforma.
Madurez en la gestión de datos con Microsoft Azure
Uno de los principales bancos de chile utiliza los servicios más avanzados de AWS para trabajar sobre la ingesta, almacenamiento, detección y modelos predictivos de data proveniente de fuentes de inteligencia de ciberseguridad.
Observabilidad en la era de los agentes: Cómo escalar operaciones inteligentes sin perder control
La visibilidad en tiempo real es clave para supervisar sistemas autónomos, anticipar incidentes y sostener operaciones digitales cada vez más complejas.
La importancia de la observabilidad en el mundo de la tecnología
Revive el webinar donde hablamos sobre importancia de la observabilidad en el mundo de la tecnología y cómo puede ser utilizada para mejorar la eficiencia, la productividad y la satisfacción de los usuarios.
Agentic AI: ¿Aliada o enemiga de la ciberseguridad?
Esta nueva tecnología autónoma promete acelerar la innovación empresarial, pero también abre interrogantes sobre control, gobernanza y gestión del riesgo en entornos cada vez más complejos.
Agentic AI: ¿Aliada o enemiga de la ciberseguridad?
Esta nueva tecnología autónoma promete acelerar la innovación empresarial, pero también abre interrogantes sobre control, gobernanza y gestión del riesgo en entornos cada vez más complejos.
Banca sin core: Las APIs redefinen la ventaja competitiva
La agilidad y la flexibilidad en el sector financiero surgen hoy de arquitecturas abiertas capaces de vincular servicios, integrarse con ecosistemas y desplegar rápidamente nuevos canales digitales.
Observabilidad en la era de los agentes: Cómo escalar operaciones inteligentes sin perder control
La visibilidad en tiempo real es clave para supervisar sistemas autónomos, anticipar incidentes y sostener operaciones digitales cada vez más complejas.
Licencias bajo presión: La hora de replantear la arquitectura
Los aumentos de hasta 1.000% en renovaciones obligan a los equipos de TI y finanzas a evaluar si conviene seguir sosteniendo la infraestructura actual o aprovechar el momento para emprender un rediseño.
Servicios financieros en la era agentic: Modernizar sin perder escala, control ni velocidad
Claves de arquitectura, datos y estrategia para convertir iniciativas de IA en capacidades operativas reales. Un paper para equipos de tecnología y decisores del sector financiero en LATAM.
La importancia de la observabilidad en el mundo de la tecnología
Revive el webinar donde hablamos sobre importancia de la observabilidad en el mundo de la tecnología y cómo puede ser utilizada para mejorar la eficiencia, la productividad y la satisfacción de los usuarios.
Ciclo de webinars de Data, Analytics & IA | Sesión #3: El impacto de IA & Analytics en el sector de media
Revive el ciclo de 3 charlas donde hablamos sobre la utilización de estas herramientas tecnológicas y su impacto en diferentes industrias, en esta oportunidad de la mano de nuestro especialista Javier Minhondo. Quien actualmente es Business Solution Architect de Nubiral.
Connect+ es una gran herramienta para incorporar conocimientos y estar al tanto de las últimas novedades tecnológicas.
Accede a nuevos contenidos audiovisuales innovadores, de forma rápida y sencilla. ¡Explora y conoce el universo tecnológico de una manera diferente y ágil!
Sistemas de recomendación con machine learning en empresas de medios digitales
Los avances en machine learning permiten que las empresas de medios digitales mejoren sus sistemas de recomendación y optimicen la experiencia del usuario.
Innovación y tecnología se nutren mutuamente y adoptarlas ya no es una opción.
Por ello, te ayudamos a capturar toda la data interna y externa, institucionalizar la toma de decisiones a través de Business Analytics, tener procesos inteligentes y automáticos y finalmente una estrategia de inteligencia artificial para optimizar la operación y predecir lo que se viene.
Acompañamos a las organizaciones en cada etapa de su adopción de inteligencia artificial, desde la estrategia y los primeros casos de uso hasta soluciones productivas que transforman procesos, reducen costos y generan valor de negocio tangible.
Sistema de monitoreo avanzado basado en multiagentes de IA generativa que permite la toma de decisiones en tiempo real a partir del análisis continuo de datos.
Repositorio de datos que puede ser almacenado en la infraestructura de la empresa, donde con flexibilidad podemos guardar el máximo de la información que recolectamos.
Del chatbot a una interacción más real. Buscamos que cada consulta se resuelva mediante el agente, reduciendo la intervención humana, sin sacrificar precisión ni trazabilidad.
De 5% a 98%: Adopción de Copilot 365 en el sector bancario
Cómo un banco líder en Argentina convirtió miles de licencias de IA generativa en hábitos de trabajo concretos, y alcanzó sus metas de adopción en un trimestre.
Cómo una plataforma de streaming deportivo aceleró la toma de decisiones al democratizar el acceso a sus datos integrando Amazon Bedrock y Redshift directamente en Slack.
Detección temprana de fallas y predicción de merma en pozos petroleros
Cómo el análisis avanzado de datos y Machine Learning permiten anticipar el deterioro en bombas electro-sumergibles, asegurando la continuidad productiva en la industria de Oil & Gas.
Transformación de la atención comercial con IA conversacional en el sector automotriz
El despliegue de un agente conversacional RAG transformó el proceso de ventas de un grupo automotriz en México, habilitando atención continua por WhatsApp y voz, agendamiento inteligente y trazabilidad completa de datos en el CRM.
Por qué más del 90% de los proyectos de IA en banca no escala (y cómo evitarlo)
Qué obstáculos frenan la llegada a producción y por qué la infraestructura, los datos y la alineación con el negocio son mucho más importantes que el modelo.
Servicios financieros en la era agentic: Modernizar sin perder escala, control ni velocidad
Claves de arquitectura, datos y estrategia para convertir iniciativas de IA en capacidades operativas reales. Un paper para equipos de tecnología y decisores del sector financiero en LATAM.
Arquitectura informática que combina una nube privada y una pública de forma que entreguen un conjunto flexible de servicios.
Esto significa que las cargas de trabajo migran de manera fluida y transparente entre un entorno y el otro de acuerdo a las necesidades que tenga la empresa en cada momento.
Optimización operativa y escalado automático para portales de gestión académica
Cómo un grupo educativo líder modernizó la infraestructura de sus plataformas estudiantiles hacia una arquitectura de contenedores, logrando despliegues automatizados y eliminando el mantenimiento de servidores.
Automatización de operaciones, mayor seguridad y reducción de costos en la nube
Estrategia integral de Cloud Operations que permitió modernizar y encapsular aplicaciones críticas, fortaleció la seguridad, automatizó la operación y proyectó significativos ahorros.
Gobernanza Cloud: Nueva era operativa en empresa líder de Servicios Financieros
Migración integral y gestión operativa proactiva en AWS, optimizando seguridad, eficiencia y agilidad para impulsar la transformación digital en empresa líder.
Banca sin core: Las APIs redefinen la ventaja competitiva
La agilidad y la flexibilidad en el sector financiero surgen hoy de arquitecturas abiertas capaces de vincular servicios, integrarse con ecosistemas y desplegar rápidamente nuevos canales digitales.
¿Cómo asegurar ambientes de APIs? ¿Cómo utilizar las tecnologías más avanzadas sin quedar expuesto? Esto y otros temas relacionados, han sido expuestos en el presente webinar.
Desde Nubiral analizamos y dimensionamos cada proyecto de tu empresa con el fin de mejorar la eficiencia de tu infraestructura TI, diseñando soluciones flexibles de alto rendimiento basadas en la experiencia de nuestros profesionales, los últimos avances tecnológicos y las tendencias actuales de cada industria.
De la fragmentación digital a una plataforma lista para el open banking
Banco Columbia tenía los productos, la visión y la ambición de crecer digitalmente. Lo que necesitaba era una plataforma que pudiera sostener ese crecimiento sin fisuras.
Migración estratégica a GitHub Enterprise para optimizar el ciclo de desarrollo
Una de las principales plataformas financieras digitales de Colombia unificó sus flujos DevOps en GitHub, fortaleciendo la colaboración y la gobernanza tecnológica.
Modernización del ciclo DevOps con GitHub Enterprise en el sector público
Institución financiera clave en Costa Rica consolidó su estrategia DevSecOps con Nubiral, migrando a GitHub Enterprise Cloud y optimizando su seguridad.
Modernización de aplicaciones: Decisiones que redefinen la agilidad del negocio
Evolucionar sistemas legacy sin frenar la operación permite potenciar el desarrollo con IA, reducir deuda técnica, acelerar ciclos de entrega y construir software preparado para adaptarse de forma continua a las demandas del negocio.
Escalamos a entornos con miles de ítems monitoreados en forma simultánea.
Además capturamos datos de comportamiento de sistemas y aplicaciones a lo largo del tiempo, para la toma de decisiones proactivas y lograr anticipar disrupciones en los servicios de tu negocio.
Infraestructura vial con monitoreo unificado y gestión de incidentes automatizada
Una empresa del sector de transporte e infraestructura modernizó la visibilidad operativa de su infraestructura on-premise distribuida implementando Zabbix 7.0 LTS con integración nativa a InvGate Service Desk, eliminando la gestión manual de incidentes y centralizando el monitoreo de entornos Linux y Windows en una sola plataforma.
Madurez en la gestión de datos con Microsoft Azure
Uno de los principales bancos de chile utiliza los servicios más avanzados de AWS para trabajar sobre la ingesta, almacenamiento, detección y modelos predictivos de data proveniente de fuentes de inteligencia de ciberseguridad.
Observabilidad en la era de los agentes: Cómo escalar operaciones inteligentes sin perder control
La visibilidad en tiempo real es clave para supervisar sistemas autónomos, anticipar incidentes y sostener operaciones digitales cada vez más complejas.
La importancia de la observabilidad en el mundo de la tecnología
Revive el webinar donde hablamos sobre importancia de la observabilidad en el mundo de la tecnología y cómo puede ser utilizada para mejorar la eficiencia, la productividad y la satisfacción de los usuarios.
Agentic AI: ¿Aliada o enemiga de la ciberseguridad?
Esta nueva tecnología autónoma promete acelerar la innovación empresarial, pero también abre interrogantes sobre control, gobernanza y gestión del riesgo en entornos cada vez más complejos.
Agentic AI: ¿Aliada o enemiga de la ciberseguridad?
Esta nueva tecnología autónoma promete acelerar la innovación empresarial, pero también abre interrogantes sobre control, gobernanza y gestión del riesgo en entornos cada vez más complejos.
Banca sin core: Las APIs redefinen la ventaja competitiva
La agilidad y la flexibilidad en el sector financiero surgen hoy de arquitecturas abiertas capaces de vincular servicios, integrarse con ecosistemas y desplegar rápidamente nuevos canales digitales.
Observabilidad en la era de los agentes: Cómo escalar operaciones inteligentes sin perder control
La visibilidad en tiempo real es clave para supervisar sistemas autónomos, anticipar incidentes y sostener operaciones digitales cada vez más complejas.
Licencias bajo presión: La hora de replantear la arquitectura
Los aumentos de hasta 1.000% en renovaciones obligan a los equipos de TI y finanzas a evaluar si conviene seguir sosteniendo la infraestructura actual o aprovechar el momento para emprender un rediseño.
Servicios financieros en la era agentic: Modernizar sin perder escala, control ni velocidad
Claves de arquitectura, datos y estrategia para convertir iniciativas de IA en capacidades operativas reales. Un paper para equipos de tecnología y decisores del sector financiero en LATAM.
La importancia de la observabilidad en el mundo de la tecnología
Revive el webinar donde hablamos sobre importancia de la observabilidad en el mundo de la tecnología y cómo puede ser utilizada para mejorar la eficiencia, la productividad y la satisfacción de los usuarios.
Ciclo de webinars de Data, Analytics & IA | Sesión #3: El impacto de IA & Analytics en el sector de media
Revive el ciclo de 3 charlas donde hablamos sobre la utilización de estas herramientas tecnológicas y su impacto en diferentes industrias, en esta oportunidad de la mano de nuestro especialista Javier Minhondo. Quien actualmente es Business Solution Architect de Nubiral.
Connect+ es una gran herramienta para incorporar conocimientos y estar al tanto de las últimas novedades tecnológicas.
Accede a nuevos contenidos audiovisuales innovadores, de forma rápida y sencilla. ¡Explora y conoce el universo tecnológico de una manera diferente y ágil!
Sistemas de recomendación con machine learning en empresas de medios digitales
Los avances en machine learning permiten que las empresas de medios digitales mejoren sus sistemas de recomendación y optimicen la experiencia del usuario.
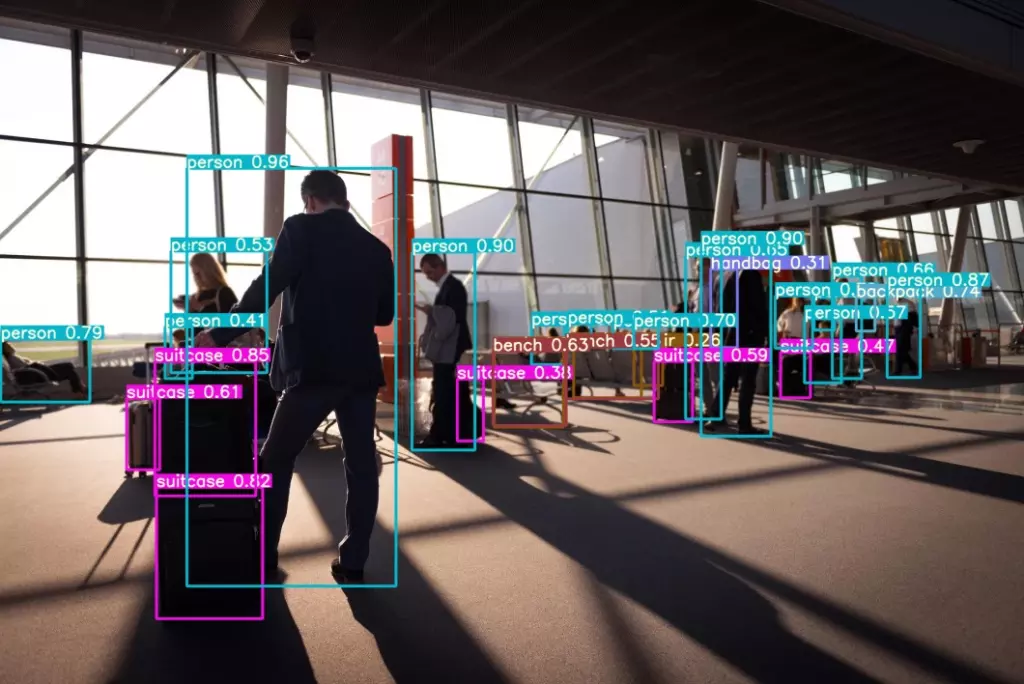
La estrategia de creación de datos sintéticos, conocida como data augmentation en imágenes, es clave para obtener el máximo valor agregado de computer vision.
Siempre se espera de los modelos de visión por computadora los resultados más precisos y adecuados. Para eso, es necesario entrenarlos previamente con el set de datos más amplio posible.
Sin embargo, en muchos casos, la cantidad de datos disponibles no resulta suficiente. El concepto de data augmentation en imágenes apunta precisamente a crear datos sintéticos para completar cuando haga falta.
Supongamos una aplicación que necesita identificar deterioro en el techo. Difícilmente haya en esa organización un banco de imágenes que muestre todos los niveles y tipos de deterioro posibles. La solución: crear los eventuales faltantes. Este es apenas un ejemplo. Existe una enorme cantidad de situaciones en la que se aplica este mismo concepto.
Un repaso al concepto de computer vision
Vale la pena recordar quecomputer vision o “visión por computadora” es una tecnología que permite a las máquinas analizar fotos y videos digitales. ¿El objetivo? Extraer sentido de ellos.
Para alcanzar ese resultado, combina exitosamente el procesamiento de imágenes con machine learning y analítica avanzada.
Así, es capaz de reconocer objetos o rostros, identificar patrones o anomalías o entender imágenes médicas, entre muchas otras aplicaciones. Incluidas muchas de las que diseñamos en nuestra área deData & Innovation.
Su uso está cada vez más difundido en industrias como salud, entretenimiento y medios digitales, manufactura, agronegocios y, especialmente, seguridad y videovigilancia.
En todos los casos, el propósito es el mismo: aprovechar las imágenes para convertirlas en información accionable para el negocio.
Usos de data augmentation en imágenes
Entre las razones que llevan a generar datos sintéticos para entrenar modelos de computer vision aparecen el aumento tanto del tamaño del conjunto de datos como su diversidad.
En el ejemplo: podría haber disponible un centenar de fotos sobre el techo deteriorado, pero todas con un nivel similar o idéntico. Con data augmentation se amplía también esa base.
En la misma línea, la creación de datos sintéticos permite garantizar que se cubren todas las condiciones y los escenarios posibles, sin margen de error ni omisiones.
Otro uso consiste en acelerar el etiquetado, ya que se puede realizar de manera automática sobre los datos generados. Esto no siempre es posible o sencillo sobre un conjunto de datos reales.
Por último, existe un motivo ligado a la seguridad y la privacidad de los datos. Con los datos sintéticos se garantiza que los reales están protegidos. Esto aplica particularmente a los casos en que hay involucrada información confidencial.
Técnicas de data augmentation en imágenes
Existen diversas técnicas de data augmentation en imágenes. Algunas de las más probadas son:
Volteo
Consiste en girar imágenes tanto de manera horizontal como vertical. Se estima que con esta técnica es posible duplicar a cuadruplicar la cantidad original de datos.
Rotación
Consiste en rotar la imagen en diferentes ángulos, cuidando en todo momento que las dimensiones originales se conserven al final de la operación. De nuevo, se estima que el factor de aumento en la cantidad de datos es del doble al cuádruple, aunque podría ser aún mayor.
Escalado
Consiste en cambiar la escala de la imagen. Se puede hacer hacia afuera (la imagen resultante será mayor que la original). También hacia adentro (menor). El factor de aumento depende de la cantidad de escalados que se realicen sobre una misma imagen.
Recorte aleatorio
Consiste en tomar una muestra aleatoria de una sección de la imagen original. Tal como ocurre con el escalado, el factor de aumento es arbitrario.
Traslación
Implica el movimiento de la imagen a través del eje X o del eje Y, o de ambos, respecto de su posición original. Una vez más, el factor de aumento es arbitrario y dependerá del número de traslaciones que se realice por cada imagen.
Tecnologías disponibles en AWS
AWS cuenta con Amazon Bedrock, que es un servicio manejado que nos permite acceder a modelos generativos capaces de generar datos sintéticos a partir de un conjunto de datos reales y de indicaciones (o prompts como se los conoce).
Amazon Bedrock es un servicio manejado que ofrece acceso a una amplia selección de FMs (modelos fundacionales por sus siglas en inglés) que son modelos con capacidad de generar contenido nuevo y original a partir de un estímulo de entrada. Estos FMs tienen la particularidad que son modelos de alto rendimiento provistos por diferentes empresas líderes en AI (como también lo es AWS).
Amazon Rekognition es un servicio manejado que permite desarrollar capacidades y modelos de Computer Vision. Particularmente con Rekognition se pueden hacer etiquetas personalizadas mediante las cuales se realizan varios aumentos de datos para el entrenamiento de modelos, como el recorte aleatorio de la imagen, la fluctuación de los colores y los ruidos gaussianos aleatorios. En lugar de emplear miles de imágenes, debe cargar solo un reducido conjunto de imágenes de entrenamiento (habitualmente, unas pocas cientos menos) específicas para su caso de uso para la consola fácil de usar.
Conclusiones
Computer vision es una rama de la inteligencia artificial (IA) que aporta un gran valor al negocio. Para eso, extrae información accionable de imágenes y videos.
Las estrategias de data augmentation permite a las organizaciones generar set de datos sintéticos para optimizar el entrenamiento de los modelos de computer vision y obtener los mejores resultados posibles.
Resuelve tanto la necesidad de cantidad de datos, como de diversidad o de etiquetado.
El éxito, paradójicamente, quedará a la vista.
¿Tu organización necesita una ayuda experta para impulsar iniciativas basadas en computer vision? EnNubiral, tenemos la experiencia, los expertos y el conocimiento de la tecnología y de la industria para acompañarte en este camino. Esperamos tu contacto: ¡Agenda tu reunión!
Por qué más del 90% de los proyectos de IA en banca no escala (y cómo evitarlo)
Qué obstáculos frenan la llegada a producción y por qué la infraestructura, los datos y la alineación con el negocio son mucho más importantes que el modelo.
Decisiones tecnológicas que deben tomarse en 2026: Las preguntas fundamentales
Las decisiones en cloud e IA no admiten más postergaciones: cómo modernizar, escalar y optimizar hoy define la capacidad de innovar, competir y crecer de forma sostenida en los próximos años.
Tres fuerzas que reconfiguran la agenda tecnológica: IA, cloud y seguridad
Automatización inteligente, optimización de costos en cloud y seguridad proactiva: tres ejes que se articulan para transformar la operación tecnológica con impacto directo en productividad, costos y resiliencia.
Por qué más del 90% de los proyectos de IA en banca no escala (y cómo evitarlo)
Qué obstáculos frenan la llegada a producción y por qué la infraestructura, los datos y la alineación con el negocio son mucho más importantes que el modelo.
Servicios financieros en la era agentic: Modernizar sin perder escala, control ni velocidad
Claves de arquitectura, datos y estrategia para convertir iniciativas de IA en capacidades operativas reales. Un paper para equipos de tecnología y decisores del sector financiero en LATAM.